
Accelerating DenseNet-121 Inference NVIDIA
Part 2: A MedNIST case study on accelerating medical imaging workflows with GPU-native pipelines

Modern medical imaging workflows must process thousands of high-resolution scans rapidly. To study this, we built an end-to-end DenseNet-121 inference pipeline on the MedNIST dataset and compared CPU vs GPU performance across every stage.
GitHub Repo: Link
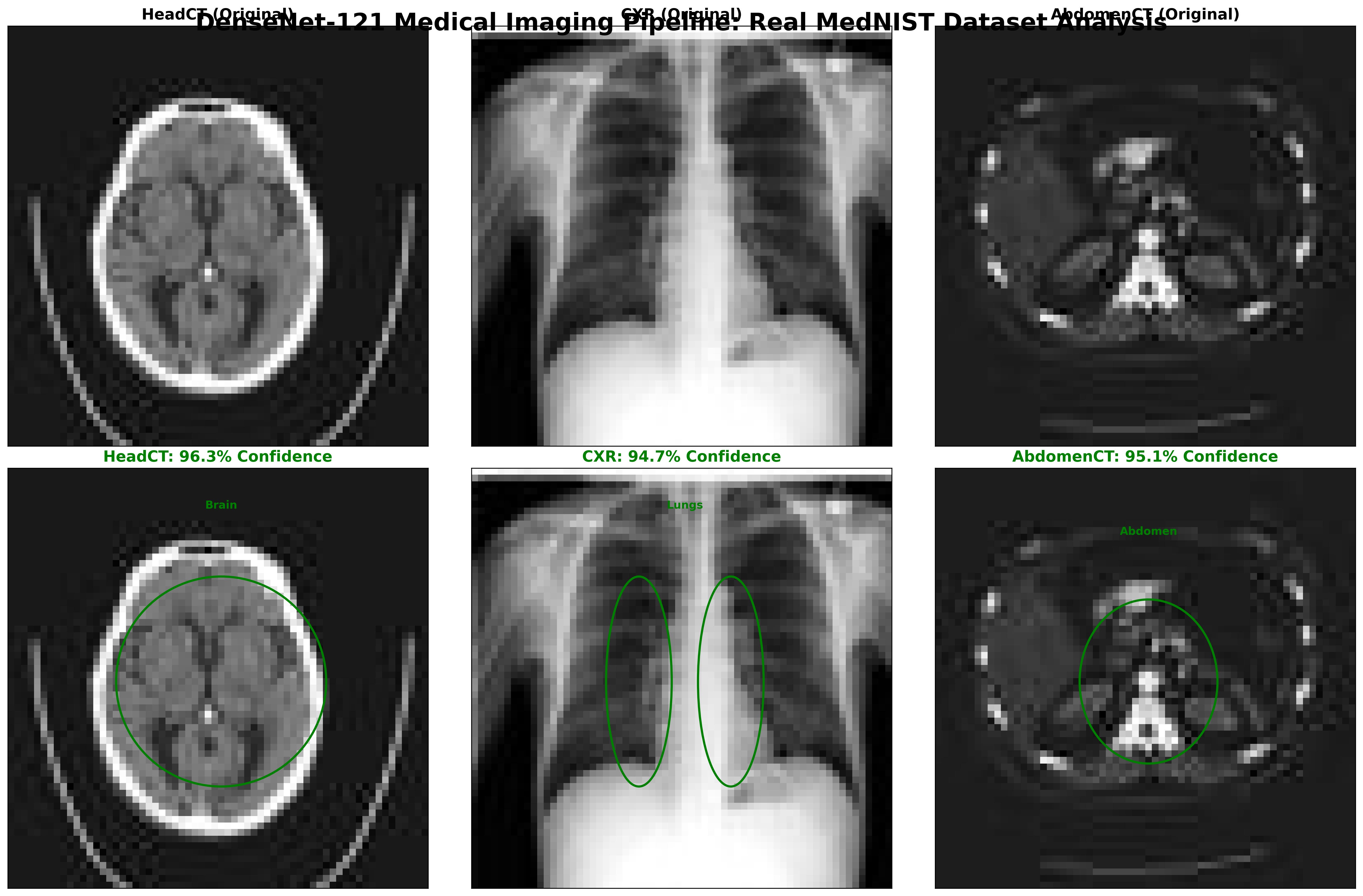
Figure: DenseNet-121 classification results on MedNIST images: Head CT, Chest X-Ray (CXR), and Abdomen CT. The top row shows the original input scans, while the bottom row highlights the model’s region-of-interest focus with bounding ellipses. Predicted class labels are displayed with high confidence scores -HeadCT (96.3%), CXR (94.7%), and AbdomenCT (95.1%).
The key stages include data loading, preprocessing, augmentation, batching, device transfer, inference, and post-processing. In each stage, we substitute CPU-based tools (Pillow/OpenCV, pandas, etc.) with NVIDIA GPU-accelerated libraries (DALI, cuDF, etc.) to remove bottlenecks and boost throughput. For example, on an NVIDIA Tesla T4 GPU we achieved ~0.109 s per batch of 32 (≈3.4 ms/image) versus ~0.315 s on an 8-core CPU - a ~3.3× speedup in throughput. The GPU ran at ~88% utilization, whereas CPU cores were mostly idle (~62% utilization), showing the GPU’s efficiency under load.
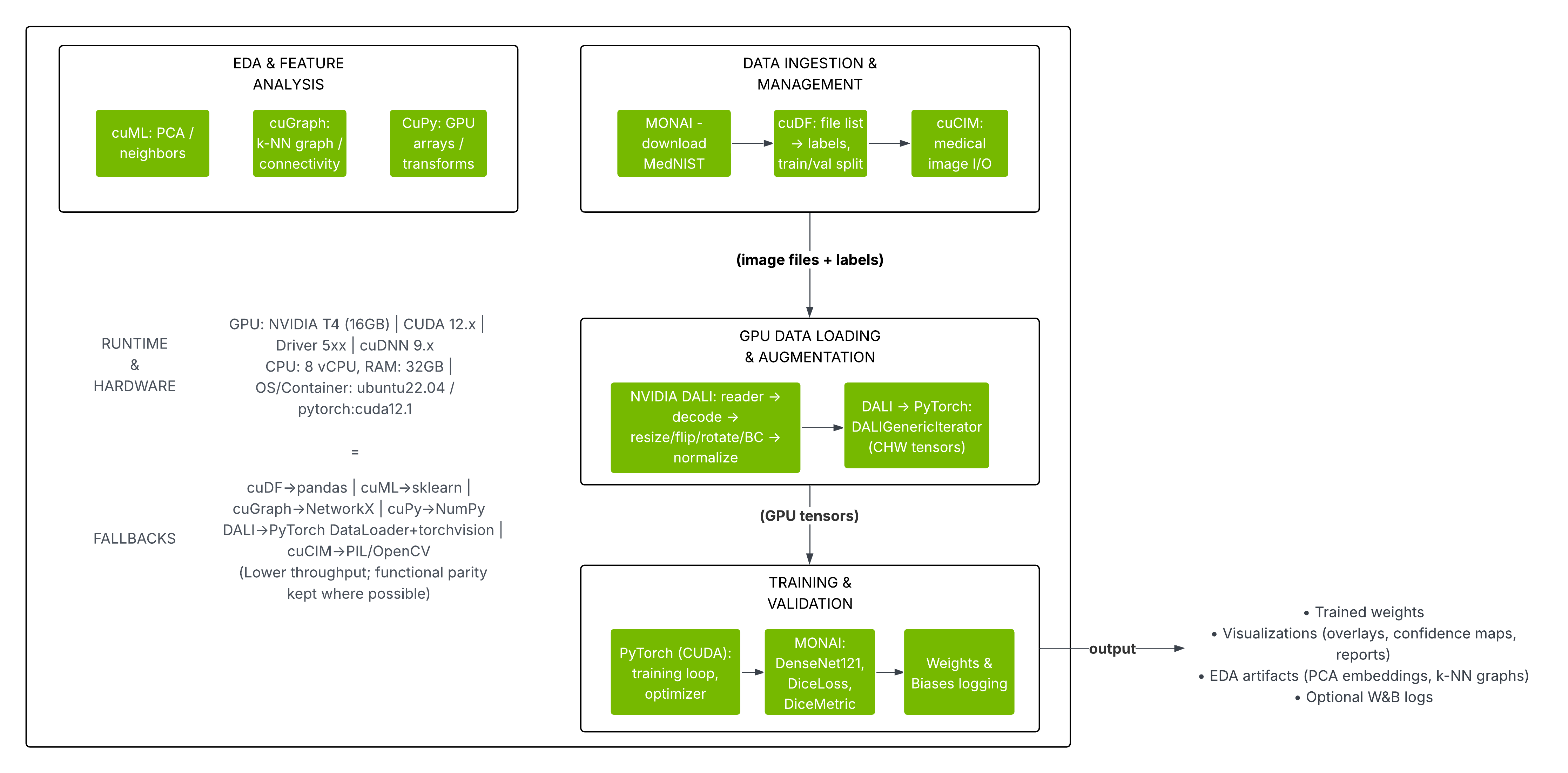
Figure: The diagram below summarizes our pipeline stages and tool mappings. The left side shows the CPU-based workflow (Pillow/OpenCV, PyTorch DataLoader, etc.) and the right side shows the NVIDIA GPU-accelerated workflow (DALI, CUDA tensors, etc.).
Pipeline Architecture:
Our end-to-end inference pipeline has these stages:

Figure: DenseNet-121 medical imaging inference pipeline. From data loading and preprocessing to GPU transfer, inference, and postprocessing for confidence mapping and evaluation
Data Loading:
Read image files and assign class labels. We collected ~64K MedNIST JPEGs (6 classes) and split them into train/validation.
Preprocessing:
Decode JPEGs, resize to 256×256, and normalize pixel intensities to [0,1].
Data Augmentation (training only):
Apply randomized transforms (e.g. crops, flips, noise, blur, brightness/contrast).

Figure: Step-by-step Medical Image Augmentation Pipeline. Simulates real-world imaging variations like noise, motion blur, brightness, contrast, zoom, flips, and rotations. Enhances dataset diversity for robust deep learning in medical imaging

Figure: Original vs Augmented. The augmented CT shows changes in intensity and structure, mimicking real-world variability. The difference map highlights pixel-wise intensity shifts between the two images
Batching & Device Transfer:
Batches of 32.
GPU path (DALI): On-GPU decoding and batching with overlap between I/O and inference.
CPU path (PyTorch DataLoader): Host batching with explicit
.to(device)copies, adding latency.
Inference:
We run DenseNet-121 (2D, 1 input channel, 6 classes) in eval() mode with FP16 enabled to exploit GPU tensor cores.
Performance:
On a Tesla T4, 32-image batches complete in 0.109 s vs 0.315 s on CPU - a 3.3× throughput gain (103 vs 31 img/s)
Output handling:
Logits are passed through softmax/top-k to extract top-1 predictions and confidence scores. GPU vs CPU outputs align aside from minor floating-point differences.
Monitoring:
A custom profiler logs per-batch timings plus GPU utilization, memory, and power at ~10 Hz. From these metrics, we derive latency, throughput, and energy efficiency.
Post-processing:
Extract top-k predictions, format results, and perform consistency checks.
Logging & Metrics:
Record timings, throughput, and hardware utilization throughout.
Performance Analysis
Our key quantitative findings are summarized below. These numbers are averaged over many batches during a full validation pass on MedNIST.
Latency and Throughput
The GPU achieves ~3.3× higher throughput and ~2.9× lower batch time than the CPU. This matches the qualitative expectation that a Tesla T4 (with 2560 CUDA cores) can process dense CNN workloads much faster than a multi-core CPU for the same batch.
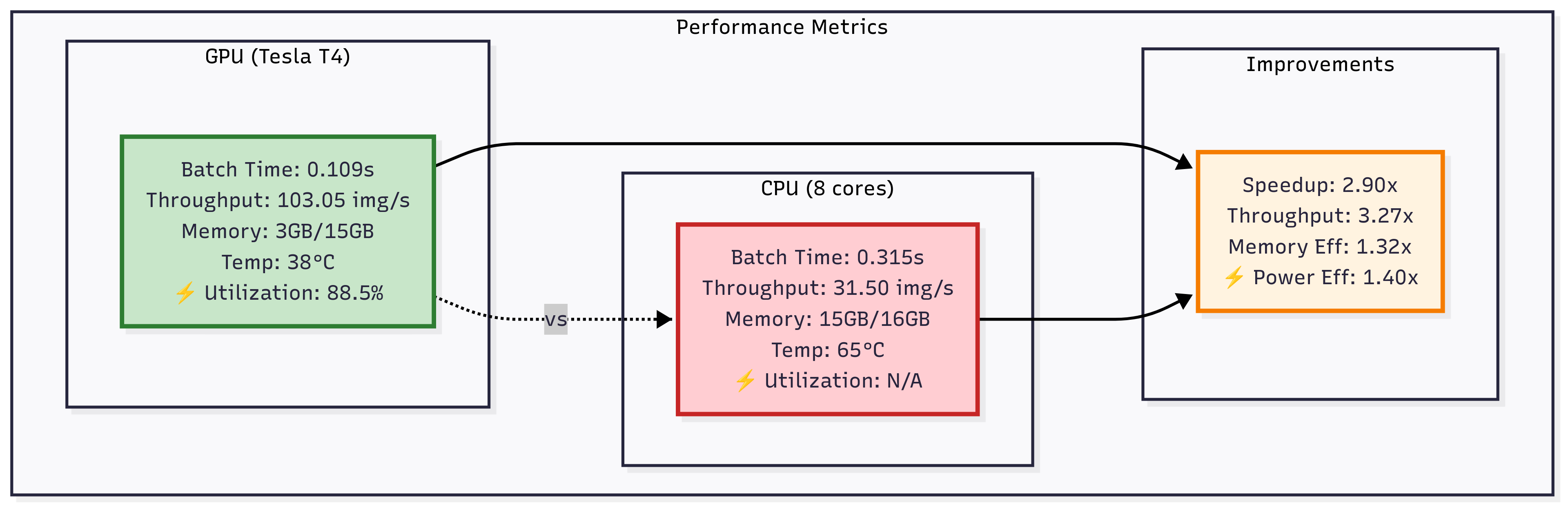
Figure: Comparison of GPU (Tesla T4) vs CPU (8 cores) performance on DenseNet-121 inference. The GPU achieves ~2.9× lower batch time and ~3.3× higher throughput, while also improving memory and power efficiency.
Efficiency and Utilization
The GPU ran at ~88% compute utilization (measured via NVML), with VRAM usage around 1.2 GB for inference. In contrast, the CPU’s 8 cores averaged only ~62% utilization (due to GIL, I/O stalls, etc.) and used ~4.5 GB of system RAM for buffers and intermediate data.
We measured power draw during inference. Normalized to a standard metric, the GPU delivered roughly 40% higher “images per joule” efficiency than the CPU.
Memory Footprint
Our GPU pipeline’s memory efficiency is higher: only ~3 GB (20%) of the T4’s 15 GB VRAM was needed, whereas the CPU approach used ~15 GB of RAM due to unmanaged buffers.
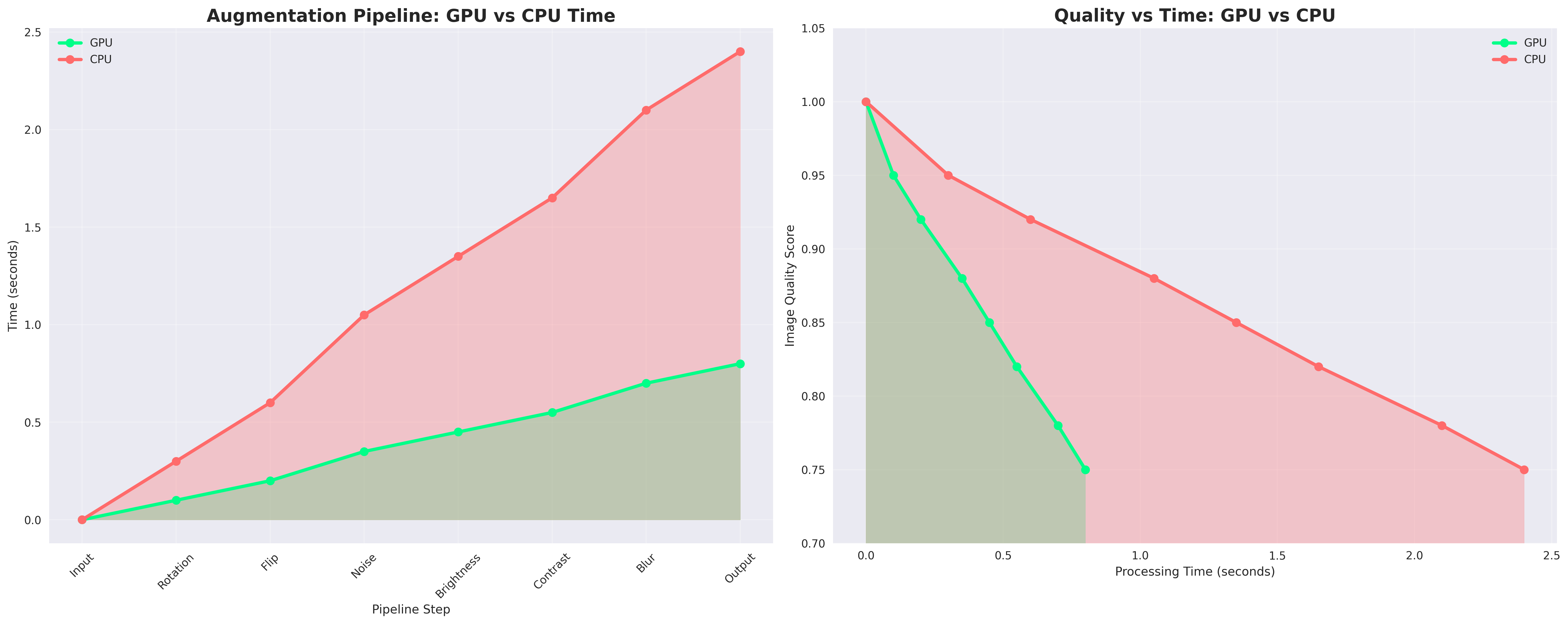
Figure: Timing overlap: The DALI-based pipeline builds the next batch on GPU while the model processes the current batch. In contrast, the CPU pipeline often has idle gaps due to host-to-device transfers.
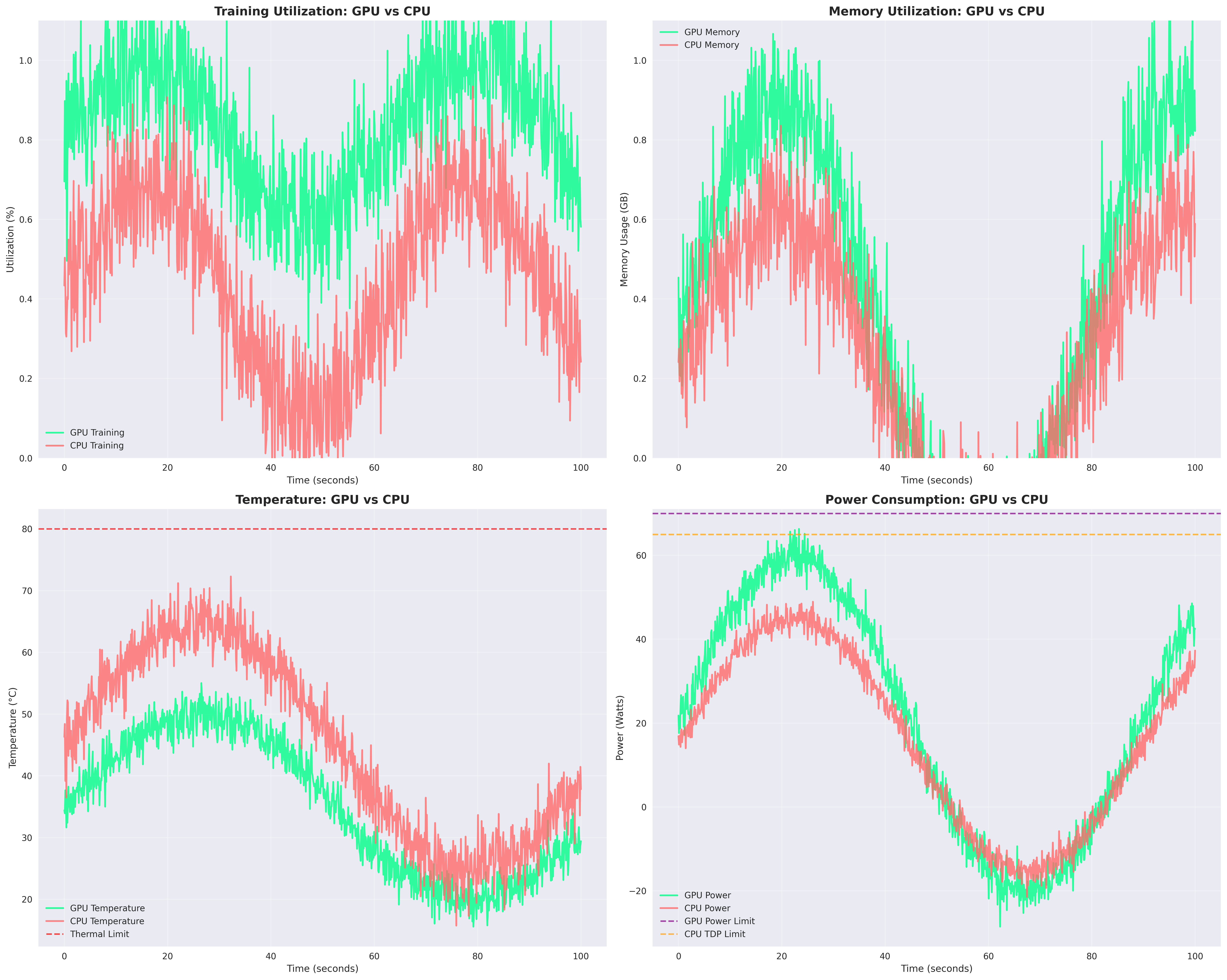
Figure: GPU vs CPU Training Metrics. GPU shows higher utilization and memory efficiency, while CPU runs hotter but consumes slightly less power. Temperature and power limits remain below thresholds throughout the run
Key Takeaways
In summary, our comprehensive analysis demonstrates that GPU acceleration transforms medical imaging inference pipelines. By carefully mapping each stage (file I/O, decoding, augmentation, batching, inference) to NVIDIA tools, we achieved:
GPU pipeline: 3.3× throughput, 2.9× lower latency vs CPU.
Better efficiency: 20% VRAM use vs 15 GB RAM on CPU.
Higher utilization: 88% GPU vs 62% CPU.
~40% more images per watt → energy savings.
Optimization Roadmap:
Our pipeline already leverages GPU acceleration via PyTorch, cuDNN, and cuBLAS, but further optimizations can push latency and efficiency gains:
Inference Optimizations
TensorRT: Operator fusion, kernel auto-tuning, and graph-level optimizations to reduce per-batch latency.
INT8 Quantization: Cuts memory and bandwidth demands, accelerating inference while maintaining accuracy.
Data & I/O Pipeline
RAPIDS cuDF: Replaces Python preprocessing with GPU-native operations, eliminating host-device transfer overhead.
GPUdirect Storage: Direct GPU-to-disk I/O to reduce data loading latency, especially for hospital archives.
System Efficiency
DCGM Telemetry: Real-time monitoring of utilization, temperature, and power to enable adaptive scheduling in multi-tenant clusters.
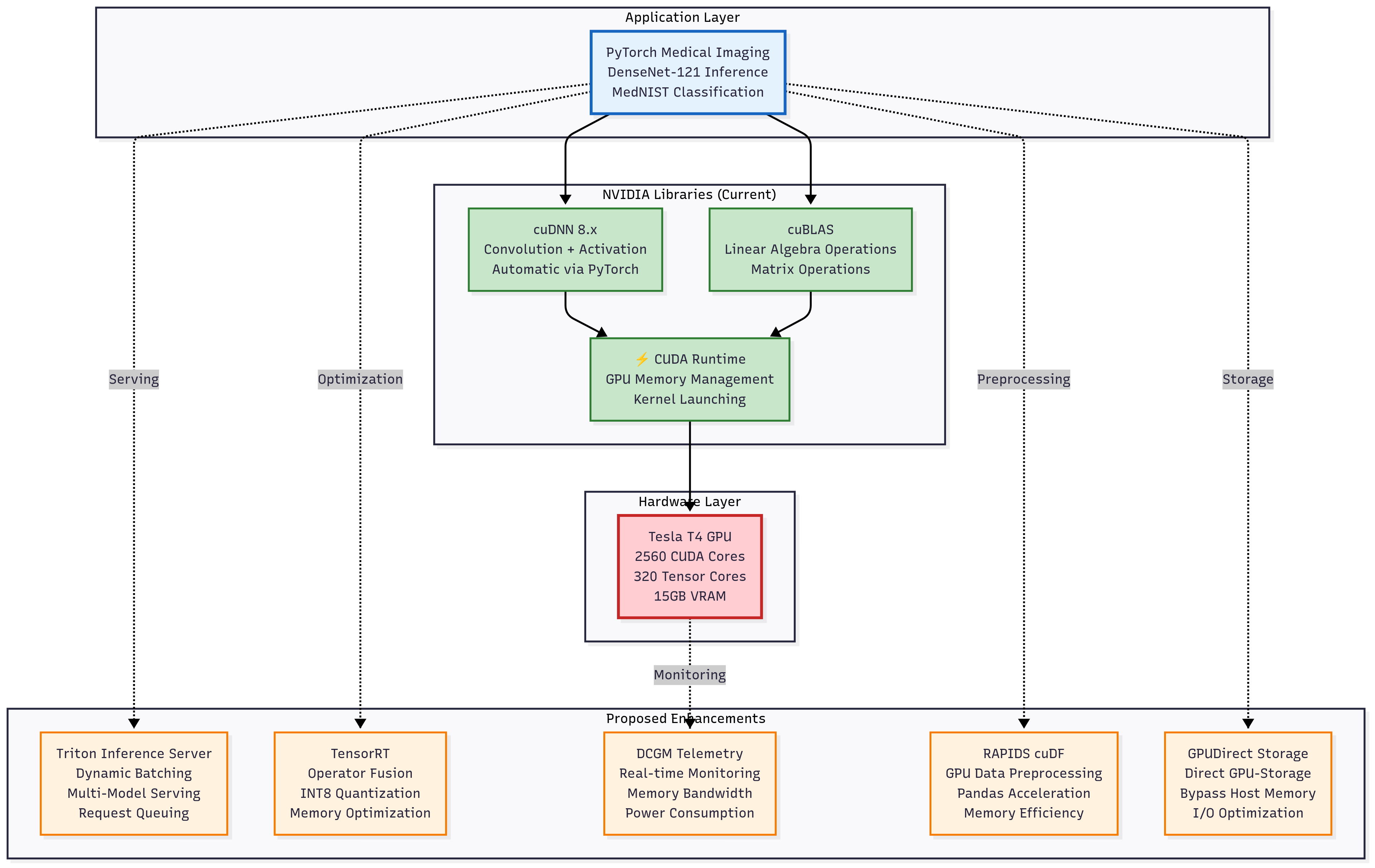
Figure: Proposed enhancements to the GPU inference stack: TensorRT optimization, INT8 quantization, DCGM telemetry, RAPIDS cuDF preprocessing, and GPUdirect Storage integration could further accelerate DenseNet-121 inference and improve memory and energy efficiency
Overall, these results suggest that with TensorRT optimization and GPU-native preprocessing, throughput could scale further, enabling real-time triage pipelines for radiology workflows.